[머신러닝 알고리즘] 가우시안 프로세스 회귀 (Gaussian Process Regression)
"예측값의 ‘잠재적인 에러’ 마저 예측하라!"

통계학과 컴퓨터과학을 중심으로 한 오늘날의 '머신러닝' 기술은 과거의 얻은 많은 양의 데이터들로부터 일종의 '패턴'을 발견해서 미래에 새로 얻게 되는 데이터들에 대해서도 의미있는 '예측'을 하는 일들을 하기 위해 발달해 왔습니다. 예를들면 집값 y와 이를 결정하는 특징들인 집의 위치 x1, 평수 x2, 건축년도 x3, ... 등의 데이터들을 모아서 상관관계 y = f(x1, x2, x3, ...)를 머신러닝 알고리즘을 통해 찾은 다음, 새로운 매물이 나왔을 때 해당 정보 x1, x2, x3, ... 를 이용해서 집값 y를 구할 수 있게 됩니다. 단순한 일인 것 같지만 미국의 온라인 부동산 회사인 Zillow (https://www.zillow.com/) 와 같은 곳이 이런 머신러닝 기술을 적극 활용한다고 할 수 있을 겁니다.
이렇게 얻고자 하는 결과가 y={'강아지' (0), '고양이' (1)} 와 같이 "discrete"한 (이산적인) 것이 아닌 집값처럼 "continuous"한 (연속적인) 값을 가지는 경우, 이런 문제를 "회귀" (Regression) 이라고 합니다. 회귀를 푸는 방법에는 다양한 방법이 있고, 각각의 장단점이 있지만 이번 포스팅에서는 "가우시안 프로세스 회귀" (Gaussian Process Regression) 라는 방법을 알아보려 합니다. 이 알고리즘의 최대의 장점으로는 예측하는 값 y와 함께 예측에 대한 불확실성 (uncertainty) 도 함께 얻을 수 있다는 것입니다. 즉 집값이 5천만원이라고 예측이 된 경우에도 이 예측이 얼마나 믿을만 한 것인지 또한 구할 수 있습니다.
이런 특징은 머신러닝을 기술적으로 잘 모르는 사람들과 소통할 때에도 큰 도움이 될 수 있습니다. 특히 예측 결과에 기반해서 큰 결정을 내려야 할 때는 이런 "uncertainty"는 유용한 정보가 될 수 있습니다. 예를들어 집값의 적정선이 5천만원이라고 예측되는 집이 4천만원에 매물이 올라왔다고 가정하겠습니다. 때문에 여러분이 일하고 있는 부동산 투자회사는 이 결과에 기반해서 바로 매입을 결정하려 할지 모릅니다. 하지만 그 예측이 약 3천만원 정도 에러가 있을 수 있다고 '잠재적인 에러'마저 예상된다면 어떨까요? 그럼 당연히 매입을 다시 생각해봐야 할 것입니다. 반대로 에러가 약 5만원 안밖으로 예상된다면 어떨까요? 여러분은 자신감을 가지고 당장 투자를 해야한다고 상사에게 주장할 수 있을 겁니다. 이것이 바로 '회귀', 그리고 '불확실성' 두가지가 동시에 이루어질 때 얻을 수 있는 이점이라고 할 수 있습니다.
가우시안 프로세스 회귀에 들어가기에 앞서 먼저 "가우시안 분포" (= 정규 분포) 와 약간의 선형대수에 대해서는 이미 숙지하고 있다고 가정하겠습니다. 최소한 한개의 변수만 다루는 단일 변수에 대해서 알고 있다고 가정하겠습니다. 그럼, 아래에는 "다변량 가우시안 분포" (Multivariate Gaussian Distribution) 을 기반으로 "가우시안 프로세스 회귀" (Gaussian Process Regression) 가 어떻게 작동하는지 설명하도록 하겠습니다.
부동산 예제 & 회귀의 목표
쉬운 설명을 위해 위 부동산 예제를 좀더 단순화 해서 계속 사용하겠습니다. 당연히 개념 설명을 위한 예제일 뿐 실제 데이터와는 아무 관련이 없습니다. 그럼 간단하게 예제에서 사용할 한개의 입력값 "X"와 예측하려는 출력값 "Y"를 정의하겠습니다.
- X = 집의 위치, 가장 가까운 지하철역과의 거리 (ex 50m, 100m, etc.)
- Y = f(X), 평균 집값 (ex 월세 100만원, 50만원, etc.)
즉, X와 Y 사이에 f(X)가 집값을 결정하는 부동산 시장의 숨겨진 함수라고 하겠습니다. 그리고 과거 부동산 거래 데이터로부터 N=3개의 관측값 (observations), 아래 빨간 "x"로 표기된 값들이 있다고 가정하겠습니다: (X, Y) 순서로, {(70, 71), (90, 60), (130, 45)}. (현실적인 데이터에서는 여러 이유의 noise 때문에 아래에서 처럼 관측값이 f(X)를 꼭 따르지 않을 수 있습니다. 하지만 알고리즘에 대한 쉬운 설명을 위해 이 예제에서는 노이즈가 없다고 가정하겠습니다.)

함수 f는 실제로는 존재하지만 우리가 아직 모르는 함수입니다. "x"표기의 관측값들만 알고 있습니다. 여기서 회귀의 목적은, 관측값들로부터 함수 f를 예측해 냄으로 새로운 x'가 들어왔을 때 y'를 정확하게 추측하는 것입니다. 예를들어 아직은 관측하지 못한 x'=100일 때의 집값 y'를 예측해 내는 것입니다.
그런데 가우시안 프로세스에서의 특징은 f(X)의 함수 결과가 X에 따라 특정한 Y로만 (deterministic) 결정되어 있다고 보지 않고, 일정한 확률적 임의성 (stochastic randomness) 를 갖는다고 봅니다. 이미 관측값이 있는 x=70, x=90, x=130에서는 관측된 y=71, y=60, y=45를 자신 있게 얻어내겠지만, 다른 X 값들에 대해서는 함수 f가 각 x마다 특정한 가우시안 분포 N(μ, σ^2) 를 따르게 됩니다. 예를들어, f(x=50)이 하나의 가우시안 분포를, f(x=100)일 때 또다른 가우시안 분포를 따른다고 이해하면 됩니다. 이렇게 함으로 새로운 x'이 주어졌을 때, 딱 하나의 예측값인 y=μ을 결과로 내는 것이 아니라 σ^2를 통해 예측되는 값의 범위를 나타낼 수도 있습니다.
회귀를 위한 큰 그림
디테일에 들어가기에 앞서, 가우시안 프로세스가 회귀를 위해 활용하는 주요 개념들부터 먼저 추상적으로 알아보고 넘어가겠습니다. 적극적으로 활용되는 아이디어 중 하나는 "x_1, x_2가 비슷하다면 y_1, y_2도 비슷할 것이다" 입니다. 위 예제를 통해 다시 말하면, 거리 "x=100미터인 집에 책정된 y=40이라는 가격은 거리 x=180의 집보다 x=110의 집의 가격을 알아내는데 더 도움이 될 것이다" 라는 것입니다. 이것은 다음 "두 개념"을 통해 구현됩니다:
- 다변량 가우시안 분포 + 커널
- 가중합 (weighted sum)
아래 수식이 이 개념들을 표현하고 있다고 할 수 있습니다. 새로운 x'에 대해 y'을 예측하려 할 때에 (x_1, y_1), ..., (x_N, y_N) 의 관측값들과 가중치 함수 w를 사용하게 됩니다. 이 w 함수를 알아내는 것이 가우시안 프로세스의 핵심인데, 이 w함수의 성질은 "x'와 비슷한 x_i에 대해서는 y_i을 많이 반영하고 비슷하지 않은 x_i에 대해서는 y_i를 적게 반영" 하도록 설계 됩니다.

조금더 구체적으로 들어가면 이 w함수는 "커널"이란 것으로 표현 가능하며 가지고 있는 N개의 관측값들로부터 이 커널을 배우는 것이 가우시안 프로세스에서의 "Learning" (학습) 입니다. 그렇습니다, [누구나 이해하는 AI — “머신러닝” 알고리즘이 실제로 하는 일] 에서 다루었듯이 여기서도 결국은 이 "가중치" w가 "학습의 대상" 이라고 할 수 있겠습니다.
누구나 이해하는 AI — “머신러닝” 알고리즘이 실제로 하는 일
"인공지능/머신러닝에 대해 “비전공자”도 궁금해할 만한 이야기" [누구나 이해하는 AI — 성공의 배경]에서 다루었 듯, 머신러닝 (aka딥러닝,기계학습) 은 최근 AI 기술 발전에 있어 가장 중추
aistory4u.tistory.com
다변량 가우시안 분포를 통한 "예측"
먼저 적합한 커널이 이미 학습되어 있다고 가정하고 새 데이터 포인트 X'에 대한 Y'의 예측이 어떻게 이루어지는지를 살펴보도록 하겠습니다. "가우시안 프로세스"라는 이름에서부터 알 수 있듯이 이 회귀 알고리즘은 (다변량) "가우시안 분포" (Multivariate Gaussian Distiribution) 의 형태를 활용해서 Y'를 구합니다.
참고로 다변량 가우시안 분포는 기본적인 가우시안 분포에 우리가 관심 있는 변량이 다수 (2개 이상) 가 있는 경우입니다. 단일 변수 Y의 경우에서는,

에서처럼 임의변수 Y가 평균은 μ, 분산은 σ의 제곱의 분포를 따른다고 표현합니다. 그러나 다변량 분포에서는,

와 같이 표현합니다. 먼저 여기에 표현된 Y, μ, Σ 모두 굻은 글씨체라는 것을 눈치 채셨을 겁니다. 왜냐하면 Y = (Y_1, Y_2, ..., Y_N) 로 N개의 변수로 이루어진 벡터이고, 비슷하게 μ = (μ_1, μ_2, ..., μ_N) 도 N개의 평균값으로 이루어진 N차원 벡터이기 때문입니다. 그러나 단일 변수 분포에서의 σ 제곱에 비교할 수 있는 Σ는 N×N 행렬로 이루어집니다.
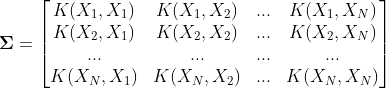
여기서 K(X_i, X_j) 라는 함수가 바로 위에서 언급한, 그리고 아래에서 더 자세히 살펴볼 '커널'입니다. 비슷한 X_i, X_j 일 수록 더 큰 값을, 다른 X_i, X_j 일수록 작은 값을 리턴합니다. (원래 다변량 가우시안 분포에서의 Σ는 공분산들로 이루어진 행렬이지만, 가우시안 프로세스에서는 빠른 연산을 위해 커널함수로 대체되어 사용됩니다.) 설명의 간결함을 위해 μ=0 으로 가정하고 진행하겠습니다. 실제 구현에서도, 관측된 각 Y에서 표본평균 m=(Y_1 + Y_2 + ... + Y_N)/N 을 빼서 μ=0 의 분포를 기반으로 Y'에 대한 예측을 진행한 후에 마지막에 표본평균 m을 다시 더해줌으로 최종 예측값을 구할 수 있습니다.
위 "부동산 예제"로 돌아오면, "X:거리"가 다른 3개의 관측값, x_1, ..., x_3 와 새로 예측을 하고자 하는 1개의 x'가 있습니다. 그럼, 다음과 같이 다변량 가우시안 분포를 표현할 수 있을 것입니다. 이 분포가 의미하는 바에 대해 좀더 설명하자면, Y_1 ~ Y_3, 그리고 Y'가 각자 정규분포를 따르나 이 정규분포들이 독립적인 것들이 아니라 X 값들의 유사성에 따라 상호 의존적으로 Y값들이 관측된다고 할 수 있습니다.

위 표기에서 3개의 관측값 (observations) 과 관련한 벡터들을 굵게 표기하였습니다. 결과적으로 맨 왼쪽 Y와 관련한 벡터와 평균 μ와 관련한 (영)벡터, K(X, X')는 각각 4차원 열벡터, K(X', X) 는 4차원 행벡터가 됩니다. 따라서 전체 커널 행렬은 4×4 차원이 됩니다. 우리의 관심은 관측 값들 (X_1, Y_1) ~ (X_3, Y_3) 과 (학습했다고 가정한) 커널 함수를 활용해 X'의 짝인 Y'를 예측하는 것입니다.
여기서 우리가 활용할 것은 "조건부 확률분포"를 구하는 것입니다. (참조) 바꿔말하면 Y_1 ~ Y_3에서 확률적으로 뽑힌 실제 관측값들을 알 때의 (조건), Y'의 가우시안 분포를 구하도록 합니다. Y'가 Y_1, Y_2, Y_3으로부터 독립적인 변수라면 이 관측값들이 큰 의미가 없겠지만, 커널 함수를 기반으로 다변량 가우시안 분포로 엮여있다고 모델링되어 있기 때문에 아래와 같이 Y'의 조건부 분포를 나타낼 수 있습니다:


모든 μ가 0로 가정되는 것을 감안하면 더 간결해 집니다.

즉 이 조건부 μ가 Y'에 대한 3개의 관측을 기반으로 한 "최적의 예측", 조건부 σ는 예측에 대한 "불확실성" (분산) 을 의미합니다. 분산 σ 이 작을 수록 예측 μ에 대한 확실성이 크다고 할 수 있습니다. (물론, 위에서 언급했듯이 Y값들의 표본 평균을 예측값 Y'에 더해줌으로 μ=0가정을 풀어줘야 최종 예측값을 구할 수 있습니다.)
앞에서 말한 가중합의 개념은 어디로 간 것일까요? 사실 위 조건부 μ를 가중합의 관점에서 해석할 수도 있습니다:


여기서 아래의 w는 N=3차원의 행벡터이고, w_i는 결과적으로 Y_i의 가중치를 의미하는 스칼라값이 됩니다. 보시다시피 w_i가 포함하는 커널행렬의 역행렬은 어떤 x'에든 고정된 값입니다. 따라서 K(X', X_i) 에 따라 w_i는 결정되며, X'와 X_i가 비슷할 수록 (커널 함수의 값이 클수록) 가중치 w_i는 커진다고 할 수 있습니다. Y_i를 더 많이 반영하게 되는 것이죠.

이런 과정을 거쳐 관측값이 없던 x'들에 대해 예측을 돌려보면 위와 같은 결과를 얻으실 수 있습니다. 검은 점선이 y'에 대한 예측 μ, 핑크색 영역이 예측의 불확실성 σ에 해당합니다. 보시다시피 관측값이 있던 세 곳에서는 예측에 대한 불확실성 (핑크) 이 아주 적은 반면, 그 지점에서 멀어지면 멀어질 수록 불확실성이 커지는 것을 보실 수 있습니다. 그리고 관측값들 사이에 있는 70~90, 90~130 지점에 있는 x'들에 대해 꽤나 실제 정확한 결과가 예측된 것을 보실 수 있습니다. 그리고 양 옆 70미만, 130 이상의 x'들에 대해서는 μ도 정확하지 않고 σ도 매우 커진 것을 확인할 수 있습니다.
참고로 위의 결과는 RBF (Radial-Basis Function) 커널을 사용했을 때의 결과입니다. 그렇다면 커널에 대해 더 자세히 알아보겠습니다.
커널의 학습
보시다시피 위 섹션에서 다룬 내용 어디에서 "학습"이라 할만한 것은 없었습니다. 앞에서도 언급했듯이 결국 가우시안 프로세스 회귀의 학습은 "커널의 학습"이라고 해도 과언이 아닙니다. 위에서 적용한 RBF 커널은 다음과 같이 생겼습니다:

d(a, b) 함수는 a, b 간의 유클리드 거리 (Euclidean Distance) 를 리턴합니다. 따라서 두 점이 같으면 커널의 값은 1이 되고, 두 점이 멀면 멀수록 커널의 값은 0에 수렴하게 됩니다. 이것을 위의 다변량 가우시안 분포에 활용했을 때, 두 x_i, x_j 가 가까우면 y_i, y_j 가 서로 비슷한 분포를 갖게 돼서 비슷한 수가 관측되게 되고, x_i와 x_j가 멀면 y_i, y_j가 서로의 분포로부터 독립적이므로 비슷한 값을 이유가 없게 됩니다. 이 포스팅에서의 간단한 부동산 예제에서는 X가 '부동산의 위치' 라는 1차원 변량이지만 더 복잡한 시나리오 에서는 높은 차원의 변수일 수 있습니다. 하지만 커널 함수가 높은 차원의 데이터 포인트끼리의 '유사성'을 하나의 스칼라 값으로 잘 반영할 수만 있다면 여기서 소개되는 방법을 문제 없이 그대로 적용할 수 있습니다. 다양한 커널들은 이곳을 참고하세요.
이 RBF 커널에서 학습할 파라미터는 바로 분모에 있는 "σ"입니다. (위 섹션에서 본 σ와 다른 것입니다) 이 σ를 현재 가지고 있는 데이터 (부동산 예제에서의 3개의 관측값) 가 가장 잘 설명 될 수 있도록 찾는 것이 "커널의 학습"이자 "가우시안 프로세스 회귀에서의 학습"입니다. σ만 알면 커널 함수가 정해지고, 커널함수를 정하면 위에서 다룬 조건부 분포를 통해 Y'를 구할 수 있기 때문입니다.
커널의 학습 방법에는 다양한 방법이 존재합니다. 여기서는 그 중의 하나인 "최대 우도 추정" (Maximum Likelihood Estimation, MLE) 의 개념적인 부분만 짚고 넘어가도록 하겠습니다. 위 부동산 예제에서 세 데이터 포인트가 있었습니다: (x_1, y_1), (x_2, y_2), (x_3, y_3). 그럼 이 데이터들과 초기에 임의로 정한 σ의 커널함수를 가지고 다음의 다변량 가우시안 분포의 확률 밀도함수 p(Y) 를 구할 수 있을 것입니다 (참조):

여기서 L, 가능도 함수 (Likelihood function) 는 밀도함수 p와 동일하나 단지 Y를 고정된 파라미터처럼 보고 σ에 관한 함수로 보겠다는 다른 표기법일 뿐입니다. Σ_σ 는 커널 행렬이며, 커널 함수는 σ를 파라미터로 갖는 RBF 커널입니다.
L함수는 확률 분포의 밀도함수이기 떄문에 0이상의 양수값이 결과로 나오게 되는데, σ가 바뀔 때마다 Σ의 커널이 바뀌며 다른 값을 확인할 수 있을 것입니다. σ에 따라 수가 최종 L의 값이 커질 수도, 작아질 수도 있을 것입니다. MLE 방법의 핵심은 이 가능도 함수 L의 결과가 "최대가 되도록 하는 σ"를 찾는 것에 있습니다. 그렇게 되었을 때, 우리가 궁극적으로 찾고 있는 f 함수, 부동산의 시장함수와 가까워 진다는 것입니다. 왜냐하면 이 함수의 확률분포에서 Y를 얻을 확률이 높았기 때문에 우리가 관측할 수 있었다는 설명에서 입니다.
정리
머신러닝의 적용 분야 중에 "회귀" (Regression) 에 대해 알아봤습니다. 그리고 회귀를 위한 여러 알고리즘 중에서도 "가우시안 프로세스 회귀" 에 대한 전반적인 개념들을 다뤘습니다. 비록 관측 노이즈가 없고 데이터 사이즈도 작은 쉬운 예제를 살펴봤지만, 약간의 수정만으로 보다 실제적인 복잡한 시나리오에도 적용 가능할 것입니다. 특히, 가우시안 프로세스의 장점은 새로운 데이터에 대한 정확한 예측 뿐 아니라 예측에 대한 "확신" (Confidence) 또한 수치로 제공합니다. 추후 포스팅에서는 보다 업그레이드된 버전의 알고리즘들에 대해 알아보고, 위에서 생략한 MLE 를 활용한 최적화 방법에 대해서도 살펴보도록 하겠습니다.
참고 자료
- "Gaussian Process - Regression" - Meerkat Statistics, YouTube Video Playlist, 2021.
- "Kriging Methods in Spatial Statistics" - Andreas Lichtenstern, Bachelor's Thesis, 2013.