💡 즉, 로봇이 직접 관측할 수 있는 지역 (Local) 적인 시각 데이터만 가지고 농업환경에서 자율주행을 가능케 하는 프레임워크를 소개합니다.
💡 그렇다면 왜 RGB 이미지만 사용하지 않고 깊이 (Depth) 데이터도 사용하려 할까요?
위와 같은 나무가 로봇의 시야 앞에 관측된다고 예를 들어보겠습니다. Semantic 세그멘테이션이 잘 이루어져 로봇 앞에 나무가 한그루 있음이 잘 인지되었다고 하겠습니다. 그럼, 이제 로봇은 충돌을 피하기 위해 옆으로 돌아가야만 할까요? 그럴지도 모르지만, 만약 저 나무가 로봇으로부터 20-30 미터 떨어져 있다면 어떨까요? 앞으로 더 전진해도 괜찮을 겁니다. 사실 RGB 프레임만으로 이런 거리 값을 예측하는 것이 가능하기도 할 것입니다. 그러나 깊이 관측 센서로 바로 알아낼 수 있다면 더 도움이 되겠죠. 또한 저자들이 밝혔듯 Depth 정보는 빛의 양에 따라 조금 다르게 관측될 수 있는 RGB 프레임의 약점을 보완해 줄 수도 있습니다.
💡 Depth 값만 활용하면 어떨까요?
위와 같은 깊이 (거리) 정보가 있다고 가정했을 때, 로봇은 앞으로 전진해도 괜찮을까요? 주행을 가로막을 만한 돌일 수도 있고 주행 가능한 잡초 따위 일 수도 있습니다. 무엇이든 간에 같이 거리에 있어서 같은 양의 정보를 주지만 RGB 프레임이 없이는 사물의 구별이 쉽지 않아보입니다. 따라서 RGB+Depth 의 모든 데이터를 사용하는 것이 로봇 주행에 도움이 될 것으로 예상됩니다.
시뮬레이션 실험을 통해 Jackal UGV (위 사진 참조) 로봇과 Intel의 Realsense d435i RGB-D 카메라를 활용합니다.
딥 네트워크 & RGB-D 이미지의 활용
Source: https://arxiv.org/pdf/2107.00700.pdf
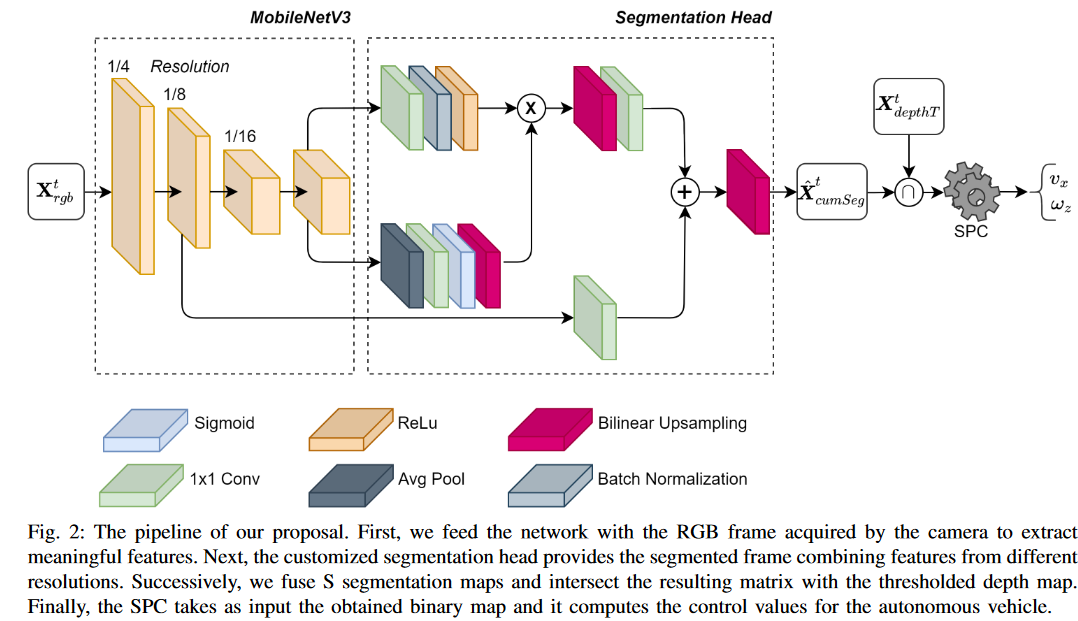
여느 다른 Semantic Segmentation 처럼 저자들은 Deep 신경망을 사용합니다. 위 그림에서처럼 기본적으로 RGB 이미지 프레임을 주 인풋으로 활용한다고 할 수 있습니다. 왼쪽에서부터 MobileNetV3와 Segmentation Head라는 레이어들을 거치면서 RGB데이터만을 활용한 나름의 세그멘테이션 결과 X_seg를 추출해 냅니다.
img_0_refined_mask.jpg at https://zenodo.org/record/4601472
💡 X_seg는 0과 1의 "이진 행렬"을 생산합니다. 논문에는 자세히 나와있지 않지만, 공개된 데이터 (위 사진 참조) 로 짐작해보면 포도밭 식물들을 1로 나머지를 0으로 구분하도록 합니다.
앞에 배경에서 소개했듯이 이 연구에서는 깊이 (Depth) 이미지를 Segmentation 된 결과 X_seg와 같이 활용해서 로봇주행을 구현합니다.
먼저, 깊이 이미지 X_depth 를 각 픽셀 마다 미리 정한 한계치 (threshold) d_depth 와 비교해서 0 또는 1의 이진 행렬 (binary matrix) 의 형태로 만들어 줍니다. 즉, i행 j열의 값이 d_depth 보다 작으면 1, 크면 0으로 만들어 줍니다. 자세한 이유는 아래에서 설명 됩니다.
Source: https://arxiv.org/pdf/2107.00700.pdf
위 수식(4) 에서와 같이 X_seg와 X_depth를 픽셀별로 교집합 연산을 하게 함으로써 멀리 있는 세그맨테이션 결과들은 0으로 만들어 줍니다.
💡 이렇게 함으로 d_depth를 기준으로 너무 멀리 있는 사물에 대한 Segmentation 정보들은 활용하지 않겠다는 뜻이 됩니다. 즉, X_ctrl은 위 세그멘테이션 그럼에서 (d_depth 미만의) 근접한 식물들만 흰색으로 표기되고 나머지는 검은색으로 나타날 것입니다.
주행 컨트롤 함수
위에서 얻은 X_ctrl이라는 시각정보의 결과물을 가지고 로봇의 주행을 제어하게 됩니다. 여기서 저자들은 SPC라는 알고리즘을 소개하는데, X_ctrl을 입력으로 로봇의 "선속도 v", "각속도 ω"를 출력으로 하는 함수입니다. 이 알고리즘의 핵심 아이디어는 다음 두가지 입니다:
X_ctrl 행렬의 "0" 를 활용하는 것입니다. 왜냐하면 X_seg에서 포도나무가 없는 곳들이 0이었고 X_depth에서는 거리가 먼 관측들이 0으로 표기되었기 때문에, 로봇이 지나갈 수 있는 "비어 있는 공간"으로 간주하는 것입니다.
일반적으로 앞으로 뻗어 있는 고랑을 따라 가기 위해 행렬의 "열" (column) 값들 확인합니다.
보다 구체적으로, X_ctrl 의 값들을 열단위로 합산을 합니다. 만약 h x w 행렬이였다면 w개의 c_1, c_2, ..., c_w 값이 구해질텐데 여기서 연속한 0의 값들끼리 클러스터링을 한다고 생각합니다. 만약 c_1, c_2, c_3만 0이고 나머지 1이라면 이 앞 세개의 값이 하나의 클러스터를 이루게 되고 만약 c_10, c_11, c_12, c_13도 0이었다면 총 두개의 클러스터가 있다고 할 수 있습니다.
더 자세히는 다루지 않겠습니다만, 만일 클러스터가 한개이면 그것을 택하고 여러개이면 약간의 후처리 (post-processing) 를 거쳐서 남은 클러스터들 중에 가장 큰 클러스터를 선택하게 됩니다. 그리고 최종적으로 선택된 클러스터의 중앙 (center) 좌표로 이동하기 위해 v, ω를 계산합니다. 더 자세한 것은 논문의 섹션 II.B를 참고하시면 됩니다.
3. 실험/평가
평가는 (1) 세그멘테이션 (2) 네비게이션, 이 두영역에 있어 이루어집니다. 특히 네비게이션은 실제 주행을 통한 데이터를 통해서, 그리고 시뮬레이션을 통해서 평가합니다.
1) Datasets
사용한 데이터는 위 링크에서 얻을 수 있으며, 1,538 RGB 이미지 파일이 세그멘테이션을 위한 바이너리 마스크와 제공 됩니다. 그 중 1,038개는 이탈리아의 Veneto라는 지역에서, 나머지 500개는 다른 지역에서 얻은 데이터입니다. 로봇이 움직이는 동안에 세대의 카메라, 한대는 앞을 다른 두대는 양 옆을 각각 향하도록 한채로 비디오를 촬영해서 이미지 프레임들을 얻었습니다.
2) Segmentation
두 기준을 활용합니다: IoU (Intersection over Union) & 픽셀 정확도 (Pixel Accuracy).
💡 각각은 무엇이고, 이 둘은 어떻게 다른 것일까요? 먼저 IoU는 세그멘테이션 마스크들끼리 비교해서 (예측: X_seg, 정답: Y_seg) 얼마나 의미있게 이 두 영역이 겹치는지를 봅니다.
예를들어 아래 그림에서 파란 영역이 X_seg, 빨간 영역이 Y_seg라고 가정해 보겠습니다. 화면 전체의 영역의 픽셀 수는 1천개, 파란, 빨간 영역은 이 예제에서 500개씩이라고 하겠습니다.
그럼 (a)에서는 두 영역이 전혀 겹치지 않았기 때문에, (X_seg ⨅ Y_Seg)=0 이고 따라서 IoU=0가 됩니다. 의미가 없는 결과물임을 잘 나타내고 있습니다.
(b)에서는 두 컬러 영역이 절반씩 겹쳐있습니다. (X_seg ⨅ Y_Seg) = 250, (X_seg ⨆ Y_seg) =750이 됩니다. 따라서 IoU=.333이 되겠네요. 당연히 (a)보다는 나은 결과입니다.
(c)에서는 두 영역이 정확히 겹쳐있습니다. 따라서 IoU=500/500=1, 가장 좋은 결과가 나왔습니다.
그럼 픽셀의 정확도를 보겠습니다. 이 기준은 세그멘테이션 마스크 영역 뿐만 아니라 마스킹을 하지 말아야할 영역도 평가합니다. True_Positives는 파란 영역과 빨간 영역이 겹친 (X_seg ⨅ Y_Seg) 의 픽셀수라고 할 수 있습니다. True_Negatives는 하얀영역으로 Y_seg에서 마스킹 되지 않은 영역이 X_seg에서도 마스킹 되지 않았는지 보는 겁니다.
이에 따르면 (a)는 True_Positives + True_Negatives = 0 + 0 임으로 정확도는 0이 됩니다.
(b)는 True_Positives + True_Negatives = 250 + 250 = 500 그리고 전체 픽셀 수가 1000임으로 픽셀 정확도는 500/1000 = 0.5가 됩니다. 마스킹 해야할 곳 절반, 하지 말아야할 곳 절반을 맞췄기 때문이라고 할 수 있습니다.
(c)는 역시 (500 + 500)/1000 으로 정밀도는 1이 됩니다.
Pixel Accuracy를 사용할 때의 단점은 무엇일까요? 바로 True_Negatives에 의해 낙관적인 평가를 할 수 있다는 것입니다. 아래 예를 살펴보겠습니다.
(d)는 (b)와 비슷한 세그멘테이션의 결과이지만 전체 픽셀 수가 2배로 늘어난 2,000개라고 하겠습니다. 따라서 True_Negatives도 1,000개가 더 늘어났습니다. 결과적으로 True_Positives + True_Negatives = 250 + 1250 = 1500 이기 때문에 Pixel Accuracy는 0.75가됩니다. (b)에서의 0.5가 (d)에서는 0.75로 향상된 것입니다.
더 큰 이미지 (2천개의 픽셀) 에서 마스킹 하지 않을 곳을 더 잘 걸러냈기 때문이라고도 주장할 수 있지만, X_seg의 파란 영역이 아무 곳도 마스킹 하지 않는다 하더라도 (0+1500)/2000 = 0.75인 것을 보면 문제가 있어보입니다.
즉, Y_seg에서 세그멘테이션을 할 마스킹 영역 (빨간색) 이나 그렇지 않은 하얀색 영역이 압도적으로 큰 경우 "픽셀 정확도"는 과도하게 낙관적인 평가 결과를 보여줄 수 있습니다.
저자들에 의하면 테스트 평균 IoU는 0.62, Pixel Accuracy는 92.7%였다고 합니다. X_seg 에서 0.9를 기준으로 더 적은 수치는 0으로 큰 수치는 1로 분류했을 때 얻은 값입니다.
또한 각 이미지마다 IoU가 특정 임계치 t이상이면 세그멘테이션이 제대로 이루어진 것으로 판단하고 계산한 정밀도 (Precision) 도 있습니다. 즉, 각 이미지마다 IoU가 t를 넘으면 제대로된 예측으로, 그렇지 않으면 잘못된 예측으로 계산해서 옳은 예측을 한 테스트 이미지들의 비율을 낸 것으로 보입니다 .
t=0.4 → Precision=96.8%
t=0.5 → Precision=85.8%
t=0.6 → Precision=62.8%
t=0.7 → Precision=24%
3) Motion Control
위에서 언급했듯이 데이터를 기록할 때 "앞", "오른쪽", "왼쪽"의 카메라로부터 다른 뷰 (view) 에서의 비디오 프레임을 저장했습니다. 따라서 이렇게 각 다른 비디오의 카테고리 별로 어떤 동작 (주로 평균 선속도 v, 각속도 ω) 을 결과로 냈는지를 확인합니다.
[Table II]에 의하면:
앞: v=0.9926 m/s, ω=0.0052 rad/s
왼쪽: v=0.6434 m/s, ω=0.3566 rad/s
오른쪽: v=0.5971 m/s, ω=-0.4026 rad/s
의 결과를 얻었습니다. 보시다시피 "앞" 에서는 평균적으로 직진 주행을, "왼쪽"과 "오른쪽"에서는 서로 반대 방향으로 턴을 하는 결과를 얻었습니다. 그리고 [Table II]에서 비교적 매우 작은 표준편차도 볼 수 있는데, 각 카테고리 별로 일관성있는 모션을 보였다는 것을 보여줍니다.
그리고 무엇보다도 여기서 자세히 다루지는 않겠지만, 학습된 Neural Network에서 덜 중요하다고 판단되는 연결들을 제거함으로써 Input → Output 의 연산을 더 효율적으로 최적화 할 수 있도록 설계했습니다. 따라서 사용한 로봇 플랫폼의 Intel i3 CPU, 4GB RAM 컴퓨터에서 매초 22개의 RGB-D 프레임을 처리할 수 있었으며, 초당 다섯번의 모션 제어 명령을 내릴 수 있었다고 합니다.
4) Simulation
Source: https://arxiv.org/pdf/2107.00700.pdf
마지막으로 Gazebo 시뮬레이터 (위 스크린샷 참고) 를 활용한 실험을 진행했습니다. 각 Row (고랑) 간에 2미터, 나무 간의 거리 1미터로 설계했으며 토양도 비포장의 흙과 비슷하게 시뮬레이션 되었습니다.
두 다른 환경에서 테스트가 진행됐는데 하나는 직선 구조, 하나는 완만한 커브들로 이루어진 구조에서 진행됐습니다 (Fig. 5, 6 참조). 그리고 각 고랑과 평행한 중앙선 (아래 하늘색 곡선) 과 로봇의 경로 (아래 빨간 점선) 들로부터 좌표간 절대값의 평균차 — MAE(X, Y) = (1/N) ∑ |x_i - y_i| — 를 구해 성능을 평가했습니다.
Source: https://arxiv.org/pdf/2107.00700.pdf
예상처럼 직선 구조에서 더 에러가 작았습니다: 직선: MAE = 0.0767미터, 곡선: MAE = 0.1947미터. 하지만 비교적 저럼한 카메라 센서들과 컴퓨터 파워를 사용한 것을 고려했을 때, 꽤 괜찮은, 더 개발해볼만 한 결과라고 볼 수 있을 것입니다.
4. 결론
저렴한 RGB-D카메라로 구성할 수 있는 농업환경에서의 로봇 주행 알고리즘을 소개했습니다.
독자적인 Deep 인공신경망 (Neural Network) 을 개발하고 최적화함으로써 실시간 주행명령이 가능하도록 했습니다.
실제 농업 환경에서 주행 데이터를 기반으로 현실적인 실험을 진행했고, 시뮬레이션을 통해서도 보다 심화된 실험을 통해 성능을 평가했습니다.